Trust, but verify
Or: How to learn by doing


Over the last fifteen years of listening to This American Life, I have often thought that pieces of music sounded familiar. Take this clip for example:
I would have bet money that Ira had reused that clip more than a few times. But with 850+ hour-long episodes, it would take me roughly 35 days to listen to the entire back catalog to confirm my theory. If you’ve ever remembered something you read years ago and then frantically Googled trying to find the original source to no avail—that’s what trying to hunt down these music clips felt like.
I recently wrote about the joy of building a project that finally answered this question. The clip above (which I call “The Curious Pivot”) has appeared in seven different episodes between 2011 and 2024. Huzzah.
You can explore the entire project, which visualizes all of the music This American Life has reused1 over the last 30 years, on my website.
Separately, I want to share a bit more about how I actually built this project as well as some thoughts about the ways in which software development is changing in this new AI world.
In order to build something like this, you used to need to mostly understand how each step worked yourself. Now that AI can do most of the implementation, you just need to be able to evaluate the output of whatever the AI is building and provide feedback. As long as you can do that, there’s a reasonable chance the project will succeed.
This shift means that a whole bunch of new (or in my case, long dreamed of but previously unlikely to succeed) projects are suddenly worth doing.
Taking the leap
When I started working on this project, I honestly had no idea how I was going to do it. I wasn’t even sure how I would download all 865 episodes without manually clicking through each one on the TAL website (side note: thank you NPR for making all of your episodes available to download). I certainly didn’t know what audio fingerprinting was or how clustering algorithms worked.
What I did know was that it was pretty likely that these hurdles I was facing, like how to programmatically download a bunch of mp3s, how to extract and isolate just the music from those mp3s, and how to group similar music clips together, had probably been solved before. I didn’t have any clue how, but I had confidence that Claude Code could figure it out and explain it to me along the way.
I also knew that I would be able to evaluate the results myself. I can listen to two pieces of music and tell you whether they’re the same after all. That meant I didn’t need to completely understand how the system worked, I just needed to do some (semi-intelligent) guessing and checking.
So I took a leap of faith. It wasn’t totally blind (I have a fair amount of experience with Claude Code), but it was a leap nonetheless because I was trusting that Claude Code could find a path through a technical landscape that I had limited familiarity with myself, and the only way to figure out whether that was possible was to actually start building.
Proof of concept
The first thing I wanted to do was figure out if it was even remotely possible that this would work. I was concerned that because the music was often interspersed with dialogue, maybe the simpler methods out there for music identification, whatever they were, just wouldn’t work.
So I started with 30 episodes, just running everything locally. Claude Code and I worked out the MVP pipeline: download episodes, detect the music segments, fingerprint the segments (i.e. create a unique signature for each segment to use for matching), and then cluster the segments that matched. When the clustering algorithm said two segments were the same music, I could play them and check.
The outputs were a bit rough (clusters were sometimes split when they should have been merged, segments occasionally got grouped that didn’t quite match), but the basic idea held, and I could tell just by listening that the segments being grouped together were mostly correct. That was enough to keep going and scale the project up to all 865 episodes.
Guess and check
Early in the project, Claude Code suggested that we use a processing technique called source separation to isolate the different audio elements from the recording. The idea was that by removing vocals before detecting and fingerprinting the music segments, we would end up with more and better matches. Naively, this seemed like a reasonable suggestion, especially because I was already concerned about the music and dialogue overlapping.
After the proof of concept had proved the general approach would work, I (and by I, I really mean Claude Code) downloaded all 865 episodes from the TAL website. Then I (again, Claude Code) set up a GPU processing pipeline on Modal to run the source separation on all of the episodes. This whole pipeline ended up costing $71, and it only cost that much because I didn’t realize the Modal GPUs were in North America and my GCP bucket was in Asia. Turns out 400GB+ of international data egress can be a bit expensive. Who knew?
The initial results of source separation looked promising. Claude Code noted that the pipeline had detected significantly more music with longer segments and deemed it a success. But then I actually started listening to the new segments, and a bunch of them were completely silent. In removing the dialogue, the source separation had sometimes removed everything else as well. Many of the segments that had music mixed with speech just became silence.
I didn’t fully understand why the source separation had failed. I had a rough sense that it was stripping everything when vocals and music were too intertwined, but I couldn’t explain why in any amount of detail or have debugged the algorithm myself. But that didn’t really matter. I understood enough to know the outputs were wrong, and that was enough. All I needed to do was recognize the problem, decide to throw the approach away, and try something simpler. Processing the original audio directly ended up working well enough on its own.
In a more traditional product development process, I would have had to spend days researching and learning about source separation before I could have attempted it. To be honest, I probably wouldn’t have even gotten that far because the juice just wouldn’t have been worth the squeeze for a hobby project like this. For $71 (even less if I had been paying closer attention) and a day or two, I could just try something that might have worked without needing to deeply understand it first. And when it didn’t work, I just moved on.
AI-assisted human verification
Midway through the project, the clustering algorithm was producing small groups of three to five instances of the same audio segment. The groups were correct, but I felt pretty confident that something was missing. Some of these segments, like the one below, are TAL staples, which I knew had appeared in more than just the handful of episodes we had identified:
I knew we were missing matches, but I didn’t know why. So I asked Claude Code for more detail on how the clustering actually worked. We talked through the algorithm, and the problem became clear pretty quickly: the clustering algorithm was trying to directly match the positions between music segments. This meant that if two segments of the same music were cut slightly differently (for example, if one started a second earlier and the other ended a second later), they wouldn’t match up even though, by ear, they were clearly the same piece.
Together, Claude Code and I landed on a sliding window approach that evaluated multiple alignments between segments in order to find the best match. This approach found dramatically more matches, and a bunch of the clusters doubled or tripled in size. The show’s closing theme went from less than a hundred episodes to 2842. But it also created a new problem: false positives. Segments that sounded quite similar but weren’t exactly the same were now being grouped together.
I could have spent time trying to tune the algorithm to reduce false positives, but that would have required expertise and familiarity that I didn’t have. Instead, I decided to build a manual curation tool in an afternoon.
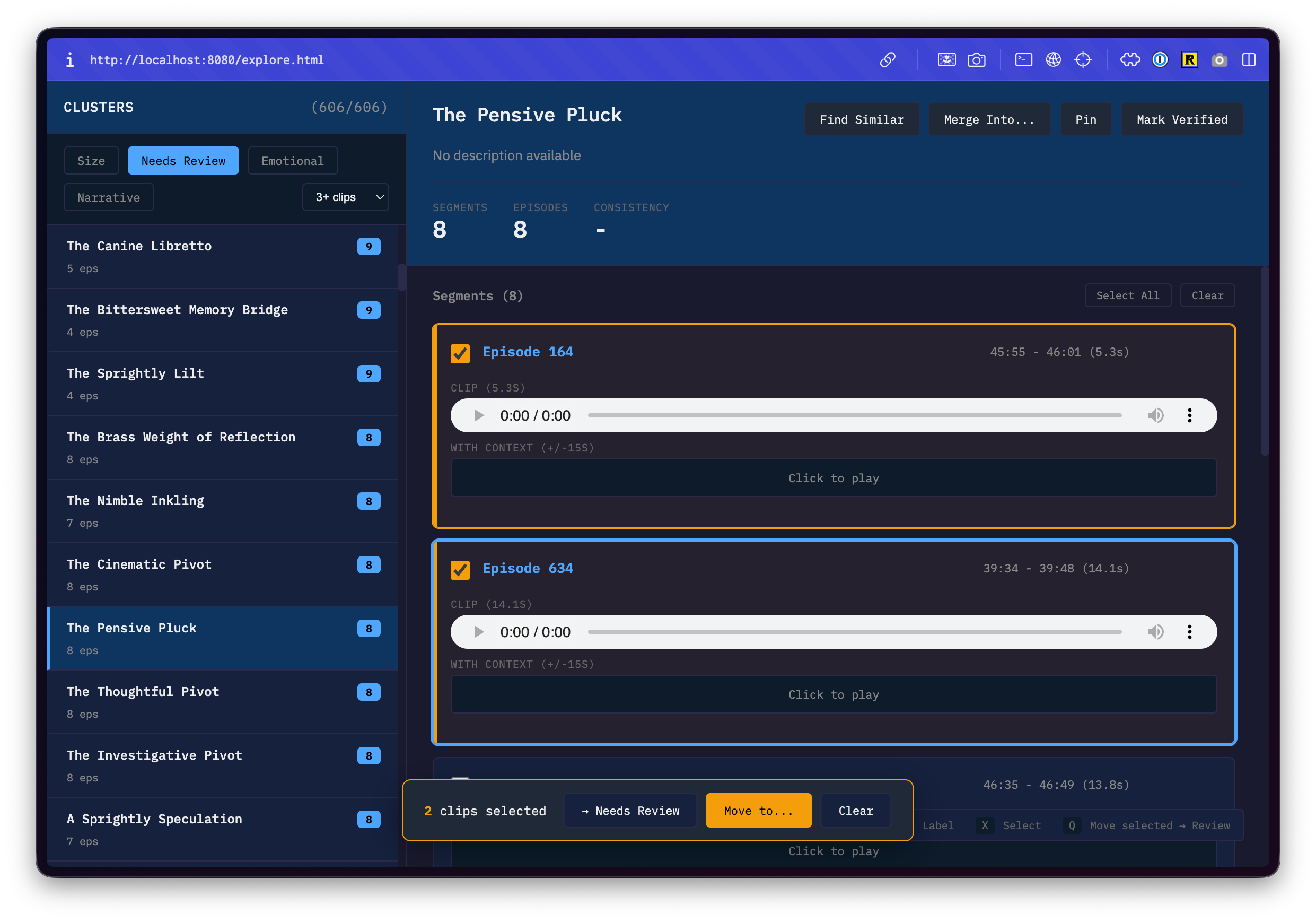
The curation tool was a simple web app that let me play audio clips, listen to what the algorithm had grouped together, and manually break apart and merge clusters that should have been combined as well as flag segments that needed further review.
In any previous era of product development, building a verification tool like this would have been a project in and of itself. A whole product, with its own planning and engineering investment, just to serve as scaffolding for the thing you actually wanted to build. The activation energy required to build something like this would have killed the project before it started.
Listening, comparing, and adjusting was a bit tedious, but it was the most direct form of evaluation I could do. After the sliding window fix, most of the clusters were already correct and just needed final touches from a bona fide, flesh and blood human.
A new approach
The whole project ended up costing me about $250 ($350 if you include my Claude Code subscription). Most of that cost ended up being covered by GCP credits that Google gave me when I signed up for an account and gave them my credit card. Even if I had paid for all of this out of pocket, I’m convinced that trusting the black box that is Claude Code and verifying along the way was the best approach. Even if it had taken 10x more attempts to find the right implementation, the total cost would still have been a small fraction of what it would have cost in time for me to build all the required expertise myself, let alone what it would have cost to hire someone to do it for me.
While I titled this section “a new approach”, this approach of defining an evaluation (or as the kids say these days, an eval) and then trusting the black box is largely how all AI model development works. Even with modern interpretability tooling, we still don’t fully understand exactly why or how ChatGPT outputs what it does. We just observe and evaluate.
So, here’s the general approach that emerged from my experience building the TAL project and the one I will take next time I want to do a project like this:
Phase 1: Write your evals
In writing, be as specific as possible about what you’re trying to build and how you’ll know whether it’s been built correctly. In other words, define what your evals are.
For the TAL project, success meant that I could visualize all of the reused music segments across all 865 episodes and that each individual cluster contained only a single, unique recurring music segment.
Phase 2: Take the leap
Build a proof of concept that demonstrates whether AI can achieve the outcome you defined according to your eval. For the TAL project, the proof of concept on thirty episodes showed that Claude Code could successfully build a pipeline to identify and cluster music segments from a limited number of episodes.
Phase 3: Build it for real
Have AI generate the code, and then evaluate the outputs as you go. For the TAL project, this meant listening to clusters to verify the algorithm was grouping segments together correctly as we scaled to more and more episodes and clusters grew.
Phase 4: Polish and refine
Once the core of the project has been successfully evaluated, apply your human judgment to add additional craft and quality. For the TAL project, this meant building the curation interface to handle false positives and refining the visualization to tell a clear story. I tried a bunch of different versions of the timeline zoom in/out speed before settling on one that really made things feel polished.
What you need for this approach to work
In order for this approach to work well, evaluation needs to be relatively cheap and the errors required for iteration need to be tolerable. For audio clustering, I could listen and check (free!) and the worst case outcome of incorrectness would have been me being slightly embarrassed. The higher the stakes, the more you will want to understand the nitty gritty implementation details, if only in order to improve your evaluation.
There’s also a recursion problem worth acknowledging. I used AI to build evaluation tools, then used those tools to evaluate AI outputs. This means that you also need to evaluate the evaluation method. As it turns out, it’s evaluation allll the way down.
In this case, I could verify whether the curation interface actually played the audio clips I asked for. I could also rely on the ground truth of my own ears. But you need at least one thing you can verify directly, with your own judgment, or the whole stack becomes untrustworthy.
This approach will also only work when the tools and approaches you need to use already exist. In this project, Claude Code and I were just stringing together pre-existing components (audio fingerprinting, clustering algorithms, cloud pipelines), not inventing something fundamentally new. But let’s be honest—stringing together pre-existing components is the majority of work, so I don’t really think this is a significant limitation.
Overall, these constraints aren’t totally unique to AI-driven development. Even when you write software without AI, edge cases you didn’t account for will reveal themselves and errors will inevitably slip through. The best you can do is hope that your tests catch the issue before it gets released, and tests are just evals by another name.
Learn by doing
There’s a nagging feeling that arises with building something this way—that the project isn’t quite legitimate if you don’t fully understand how it works. That you’re taking shortcuts, or that the work doesn’t really count if AI did most of the implementation. I felt that way during multiple parts of this project, even as I was successfully building something I’d imagined building for years.
But that feeling is wrong (or at least misguided). The work is no less real because I didn’t write any of the code or understand all of the algorithms (truth be told, I am quite bad at math). I defined what success looked like, evaluated the outputs at every stage to make sure we were getting closer, and provided the domain knowledge that Claude Code was missing (it’s never actually heard an episode of This American Life). I trusted the machine to handle the technical wayfinding, but the judgment was still mine. That’s product management.
If you can clearly articulate what good looks like and validate the outputs yourself—a much lower bar than building expertise in every component yourself—then trust the process and take the leap. The cost of trying (and failing) is low. The cost of not trying is every project you never end up starting because the activation energy feels too high.
The visualization only includes instances where a clip was used at least three times. There are a lot of clips that were only used twice, but that didn’t seem quite as intentional to me
The signature closing theme (”The Sophisticated Coda”) appears in 284 of the 530 episodes before July 2014, after which it disappears entirely. This coincides with TAL’s switch to self-distribution when Public Radio International (PRI) stopped carrying the show in 2014. I also manually verified that not all recordings prior to this date contain the closing theme.